In Searching Counter Examples for Ramsey Number
This is a project I did in my undergrad, so I might forget some of the details. Also some of the design choices might seen stupid for now, but I am writing them down anyway just for note-taking. The codes on Github. And here is the presentation we have. I assume the readers of this post have basically knowledge of computer science, like graphs, but not necessarily mathematics (I am really bad at mathematics in fact).
What is Ramsey Number?
According to Wolfram Research, it is to Find the minimum number of guests that must be invited so that at least m will know each other or at least n will not know each other. The solutions are known as Ramsey numbers. To phrase it in Computer Science word, for $R(n,m)$, it is to find a complete graph with minimum vertices such that if we color edges in two colors, there is no monochromatic n-cliques and m-cliques in any edge labelling. A counter example of $R(n,m)$ is basically a graph with a a labeling that contains monochromatic clique(s).
How hard is this? Well we know that $R(3,3)=6$, $R(4,4)=18$, and we don’t know anything above $R(4,4)$. For $R(10,10)$, the current bounds are $798$ to $23556$. In the project, we are to design an algorithm/system that make use of basically endless computing power from both super-computers (XSEDE, CondorHTC), and cloud platforms (AWS) to find the largest counter example of $R(10,10)$.
Some Basic Ideas
We didn’t do edge coloring in our implementation. Instead, we split the graph into two graphs by the colors of the edges, and count the cliques in both graphs. There are various reasons we make this decision, which we’ll talk about later. For now just remember the setting that we are dealing with two graphs now.
The basic flow of the algorithm is the following:
- Start from a random very small graph (like 20 vertices), split it into two, and
work on this first.
- Count the cliques of two graphs. If the sum of the cliques of two graphs is 0, we are done with this graph.
- If not, we need to “flip” edge(s), namly remove edge(s) from one graph and add it to the other graph. Then count the cliques again. Repeat until the sum is 0.
- After we done with a graph, record the number, and add a vertex/vertices to that graph to form a new graph, for reason being that the old graph doesn’t have any cliques, so adding vertices to that graph is likely to not produce many cliques. And then repeat the process.
So there are a few things we need to design/implement, which we’ll talk about later:
- How do we count cliques?
- Well it is a NPC problem so we might just do the dummy method, but infact using a smarter method would help.
- How do we choose which edge to flip?
- We can do some greedy search like: try one edge, if good (sum of the cliques goes down) then keep the change, if not good then discard the change and try another one, and keep going until the count gets to 0. This won’t get us very far as we will reach some “local minimum”, in which case we’ll need some ways to get out of it.
- How do we add vertices to old graph?
- We can blindlessly add vertices, or we might want to have some smartness.
- How do we make maximum use of those compute power?
- This might sound stupid, but because we have many different platforms/computers located all around the world, we’ll need some kind of protocol, and even build a distributed system to make use of them.
What Doesn’t Work
This section will cover some methods to try to solve some of the above questions and doesn’t work quite well for us. It doesn’t mean that it won’t work well in general, but just us.
Simulated Annealing/Stochastic Tunneling
Simulated Annealing(SA), quoted from Wikipedia, is a probabilistic technique for approximating the global optimum of a given function. Here is the pseudocode:
- Let s = s0
- For k = 0 through kmax (exclusive):
- T ← temperature(k ∕ kmax)
- Pick a random neighbour, snew ← neighbour(s)
- If P(E(s), E(snew), T) ≥ random(0, 1):
- s ← snew
- Output: the final state s
And stochastic tunneling (STUN), also quoted from WIkipedia is an approach to global optimization based on the Monte Carlo method-sampling of the function to be objective minimized in which the function is nonlinearly transformed to allow for easier tunneling among regions containing function minima.
Both of the above methods are randomized simulation methods. Here is the major drawbacks, due to which we discard them in our final implementation: Setting Parameters. The most vaguely described aspect of various simulation/ML algorithms in my opinion is how to set the proper parameters. Most of them say something like “we pick $k=2,t_0=5,s=100$ for our experiment because they work the best; choose your own set of parameter in production”, which equivalently says “choose whatever parameters you feel like”. It is quite hard in our case to determine what parameter works best for us as the problem size is so large that even parameters themselves need to be adjusted during different phases of simulation. There is also something called Detrended Fluctuation Analysis (DFA), which is a way to detect if the simulation reaches a local minimum and thus adjust the parameter to work better. But the problem is, the algorithm for adjusting parameters also needs some parameters to work well…So basically you have to set at least one parameter in order to get things working. And to get things working faster, especially in such a large problem space, you really have to set parameters well. In our case, due to lack of experience, we can’t get things run fast enough, and therefore we basically give up for any kinds of randomized simulation algorithm.
Clique Counts Approximation
We were also considering to first get an approximation of clique count of 0, after that then use the exact clique counting algorithm. The reasoning is that the approximation is much much faster than the exact one, which is a NPC problem. But it was just a brainstorm and it didn’t actually work well for us, as we found a even smarter algorithm.
Our Design and Implementation
This section will cover all the design/implementation details in our final product. It is splitted into several sections for clarity.
Clique Counting
We use the algorithm described here, which counts cliques using MapReduce. The idea is basically to split the problem of counting a $n-clique$ into a few $(n-1)-clique$ problems and suming them up. The sub-problems can be splitted accordingly depending on how many cores/machines we have to do the computation. This is much faster than the dummy clique-counting algorithm, as it cheats by parallelizing the problem.
Tabu Search
Tabu search is basically a greedy algorithm for flipping edges, but with an improvement of having a history, called tabu list, usually implemented by a linked list, so that it won’t search on the same thing twice. Having a history to record what its moves are, and when it hits a local minimum, becasue it doesn’t take the steps that is used before, it’ll just “back-up” from the local minimum, i.e. accepting a move that is worse because it has not choice, and start searching from there. Note that the tabu list might have some maximum length, due to 1. memory issue, and 2. we might want to revisite the same spot twice in the future.
The original form of tabu search doesn’t work quite well in our case:
- Our graph is large. To represent a 300 vertices graph needs at least $300x300$ bits matrix, and we might need to store hundreds of them. Memory is an big issue for us if we need a large tabu list.
- Our algorithm will need to be distributed to make the maximum use of the compute power we have. So should we have a local tabu list for each worker, in which case the workers will not collaborate well, or should we have a global tabu list, in which case memory becomes a even larger issue for us. We could in fact use a database for global storage, but access data from a disk is too slow.
We solve (we think) the above two issues by using another data structure for storing history, described below.
Bloom Filter
As you all know, bloom filter is a super space efficient data structure with some false positive probability but no false negative, as it only stores bits instead of the original data. In other words in our case,
- If the bloom filter says the step we take is not taken before, then we know that for sure (with probability of 1)
- If it says the step is taken before, we know that it is the case for some probability $p$
The important point here is that, the false positive rate $p$, along with the desired number of graphs we want to store, can be configured to meet our needs best. For example, in our case, we make the maximum number of graphs it can store be 40,000,000, and $p$ be $1.0E^{-10}$, then we have the memory cost of $228.53MB$. Note that the expected number of false positive instnaces is 0.004, which means that even if we use up all the spaces of this bloom filter, we are extremely unlikely to have even one instance of false positive. Even in the case we have false positive, the assumption here is that the problem space is so large that it is ok if we miss a couple steps; there are plenty of other steps we can take to make it work.
The Main Trick
Not all men are equal, and not all edges are equally likely to be flipped. And moreover, we don’t actually need to count $10-cliques$ every time we flip an edge. Here is the trick:
- When move to larger problem size
- Count 10 cliques once
- Maintain a Map: {Edges} -> {clique counts}
- After the first and only 10-clique count check, we start to flip edges
- During flipping, we also maintain the “complement” of the graph $G$, because:
- To check $R(m,n)$ is the same to check:
- $m-clique$ on $G$
- $n-clique$ on $G^c$
- To check $R(m,n)$ is the same to check:
- When we test if flipping one edge works, we need to update the corresponding {Edges} -> {clique counts} map. We get a list of intersected nodes of that edge and search for (n-2)-clique
- During flipping, we also maintain the “complement” of the graph $G$, because:
This is super hard to describe in words for me, so here are the relavent exerted codes.
void updateEdgeToClique(Edge edge) {
edgeToClique.remove(edge);
Edge flip = flip(edge);
Map<Edge, Long> minus = new HashMap<>();
Map<Edge, Long> plus = new HashMap<>();
Map<Integer, Long> nodesMinus = new HashMap<>();
Map<Integer, Long> nodesPlus = new HashMap<>();
long oldCount = countCliquesSub(edge, true, minus);
long newCount = countCliquesSub(flip, true, plus);
for(Map.Entry<Edge, Long> entry : minus.entrySet()) {
changeEdgeToClique(entry.getKey(), -entry.getValue());
nodesMinus.putIfAbsent(entry.getKey().node1, new Long(0));
nodesMinus.putIfAbsent(entry.getKey().node2, new Long(0));
nodesMinus.put(entry.getKey().node1, nodesMinus.get(entry.getKey().node1) + entry.getValue());
nodesMinus.put(entry.getKey().node2, nodesMinus.get(entry.getKey().node2) + entry.getValue());
}
for(Map.Entry<Edge, Long> entry : plus.entrySet()) {
changeEdgeToClique(entry.getKey(), entry.getValue());
nodesPlus.putIfAbsent(entry.getKey().node1, new Long(0));
nodesPlus.putIfAbsent(entry.getKey().node2, new Long(0));
nodesPlus.put(entry.getKey().node1, nodesPlus.get(entry.getKey().node1) + entry.getValue());
nodesPlus.put(entry.getKey().node2, nodesPlus.get(entry.getKey().node2) + entry.getValue());
}
for(Map.Entry<Integer, Long> entry : nodesMinus.entrySet()) {
Edge temp1 = new Edge(Math.min(edge.node1, entry.getKey()),
Math.max(edge.node1, entry.getKey()));
Edge temp2 = new Edge(Math.min(edge.node2, entry.getKey()),
Math.max(edge.node2, entry.getKey()));
changeEdgeToClique(temp1, -entry.getValue() / 7);
changeEdgeToClique(temp2, -entry.getValue() / 7);
}
for(Map.Entry<Integer, Long> entry : nodesPlus.entrySet()) {
Edge temp1 = new Edge(Math.min(flip.node1, entry.getKey()),
Math.max(flip.node1, entry.getKey()));
Edge temp2 = new Edge(Math.min(flip.node2, entry.getKey()),
Math.max(flip.node2, entry.getKey()));
changeEdgeToClique(temp1, entry.getValue() / 7);
changeEdgeToClique(temp2, entry.getValue() / 7);
}
if(newCount != 0) {
edgeToClique.put(flip, new AtomicLong(newCount));
}
current.set(current.get() + newCount - oldCount);
}
private long countCliquesSub(Edge edge, boolean change, Map<Edge, Long> edgeToClique) {
int currentSize = client.getCurrentSize();
List<Integer> intersect = getIntersectNodes(edge);
AdjListGraph g = new AdjListGraph();
g.edgeToClique = edgeToClique;
Collections.sort(intersect);
for(int i = 0; i < intersect.size(); i++) {
for(int j = i + 1; j < intersect.size(); j++) {
int node1 = intersect.get(i);
int node2 = intersect.get(j);
if(hasEdge(new Edge(node1, node2))) {
g.addEdge(Integer.toString(node1), Integer.toString(node2));
}
}
}
return g.countCliquesOfSize(8, change);
}
List<Integer> getIntersectNodes(Edge edge) {
List<Integer> intersect = new ArrayList<Integer>();
if(edge.node1 >= currentSize) {
for(int i = currentSize; i < currentSize * 2; i++) {
if(i == edge.node1 || i == edge.node2) {
continue;
}
Edge test1 = new Edge(Math.min(edge.node1, i), Math.max(edge.node1, i));
Edge test2 = new Edge(Math.min(edge.node2, i), Math.max(edge.node2, i));
if(hasEdge(test1) && hasEdge(test2)) {
intersect.add(i);
}
}
} else {
for(int i = 0; i < currentSize; i++) {
if(i == edge.node1 || i == edge.node2) {
continue;
}
Edge test1 = new Edge(Math.min(edge.node1, i), Math.max(edge.node1, i));
Edge test2 = new Edge(Math.min(edge.node2, i), Math.max(edge.node2, i));
if(hasEdge(test1) && hasEdge(test2)) {
intersect.add(i);
}
}
}
return intersect;
}
void changeEdgeToClique(Edge edge, long delta) {
if(delta <= 0) {
edgeToClique.get(edge).addAndGet(delta);
if(edgeToClique.get(edge).get() == 0) {
edgeToClique.remove(edge);
}
} else {
edgeToClique.putIfAbsent(edge, new AtomicLong());
edgeToClique.get(edge).addAndGet(delta);
}
}
And here is a picture illustration:
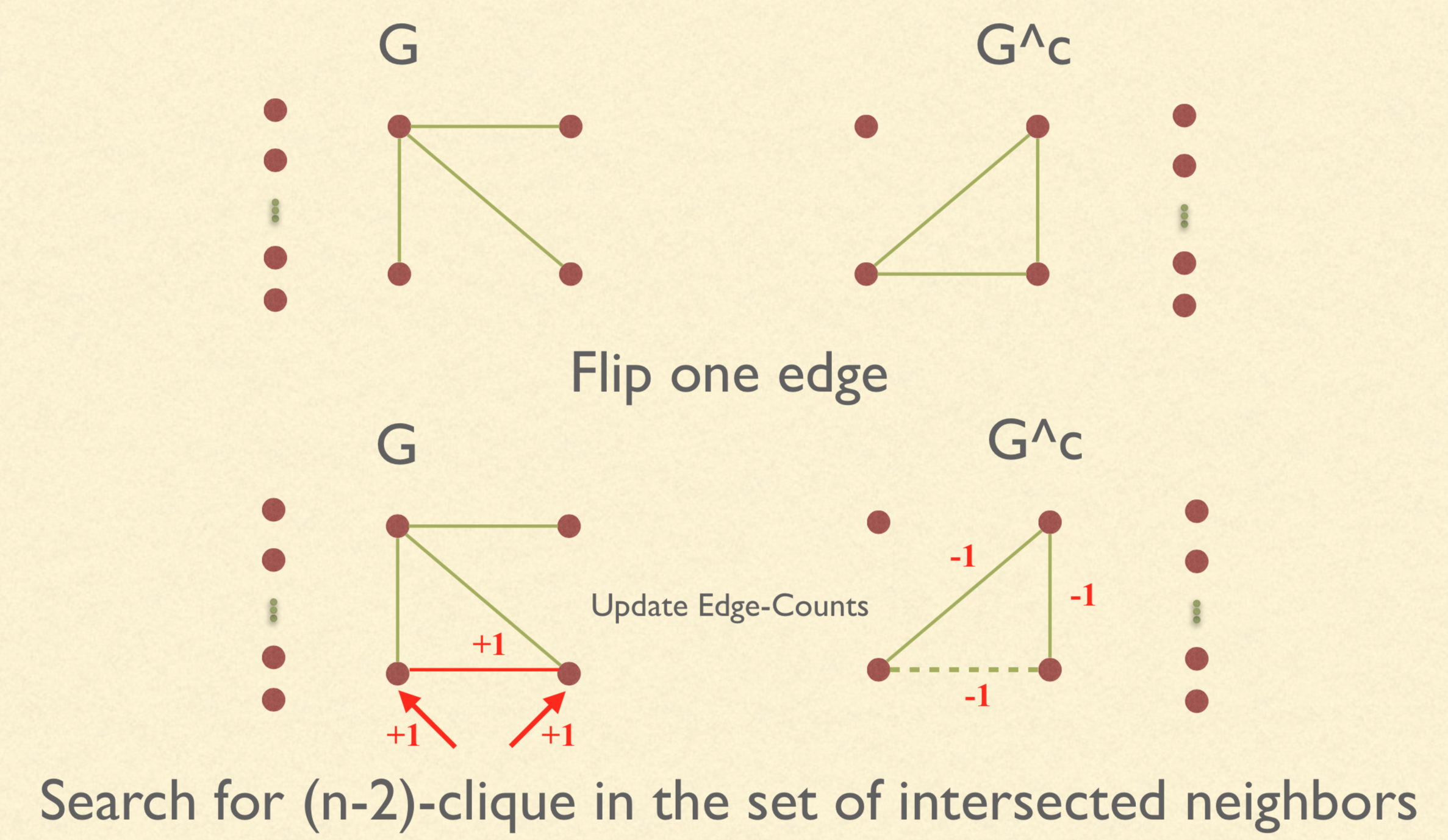
Again all codes are on Github and here is the presentation.
Server-Client Protocol
In our implementation, this part is nothing really special but a bunch of TCP connections. The information exchanged includes:
- Current graph size
- Current graph
- Current clique size
- The {Edges} -> {clique counts} map
- Best clique so far.
Basically each worker does thei own search until one of them finds a solution to current graph size, and then all of them move on to the next graph size. They are “always” doing searches in different graphes because of the global bloom filter we have. The main server might be down so we also have a backup server to take care of this.
All in all, the client-server implementation is pretty basic in the sense that they are just a bunch of TCP connections, no HTTP, no Raft consensus, no monitoring.
Summary and Possible Improvements
- It is better to use more up-to-date technologies :)
- Opensource solution for server cluster with consensus by Raft/Paxos
- Opensource solution for monitoring and visualized search progress
- Some other tricks like we can skip to next prime graph size, which I heard is better.
Comments