Memory Management
This lecture will attempt to cover the various concepts that are important to the memory management functions that most operating systems must perform.
Linking and Loading
- program addresses are logical, machine addresses are physical
- linking – resolving logical addresses relative to the entire program
- .o files have logical addresses
- when multiple .o files are linked, addresses must be altered
- symbol table contains necessary information
- Unix utility ld() is the linker
- loading – the introduction of a program into physical memory
- logical program addresses must be converted to physical machine addresses
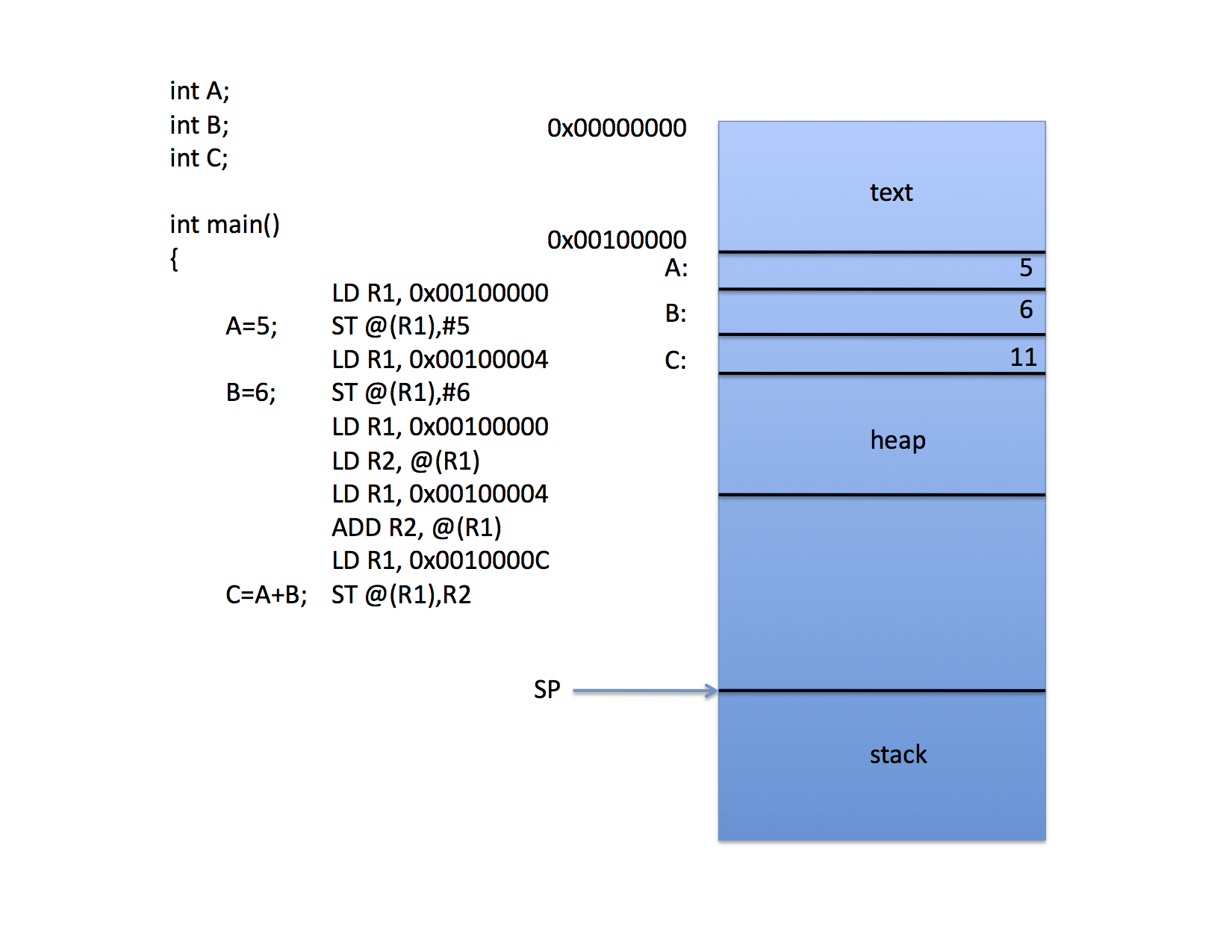
When the code is loaded into memory, the compiler generates code so that variables are accessed via offsets from memory locations that are determined when the program boots. For example, consider the fictitious code depicted in the following figure:

The local variables A,B, and C are all addressed via the SP register by computing a memory address by adding the contents of the SP to the contents of an offset register (R1 in the figure).
Thus, when the program is loaded into memory, the loader “knows” that the stack pointer will start at location 0x7f00000c and it tells the OS to initialize the SP with this value. The call to foo() can been compiled to pus the space for three integers onto the stack and the code accesses the variables indirectly through the SP and individual offsets for each variable.
That’s fine for the stack where there is always a machine register that defines the top of the stack. CPUs do not have explicit registers for the other segments in a Linux a.out process image, however. Thus, when accessing global variables, the compiler must either “burn” a register for the start of the data segment (which is costly since there aren’t enough registers as it is) or it must “hard code” addresses (as in the following figure):
Again, the compiler has chosen to access memory via indirect addressing, but it does so with address constants to save registers for computation.
This work fine when
- the program is always loaded at the same location in memory
- the program is the only program in memory
However, consider what happens if there are to be two processes in memory at the same time.
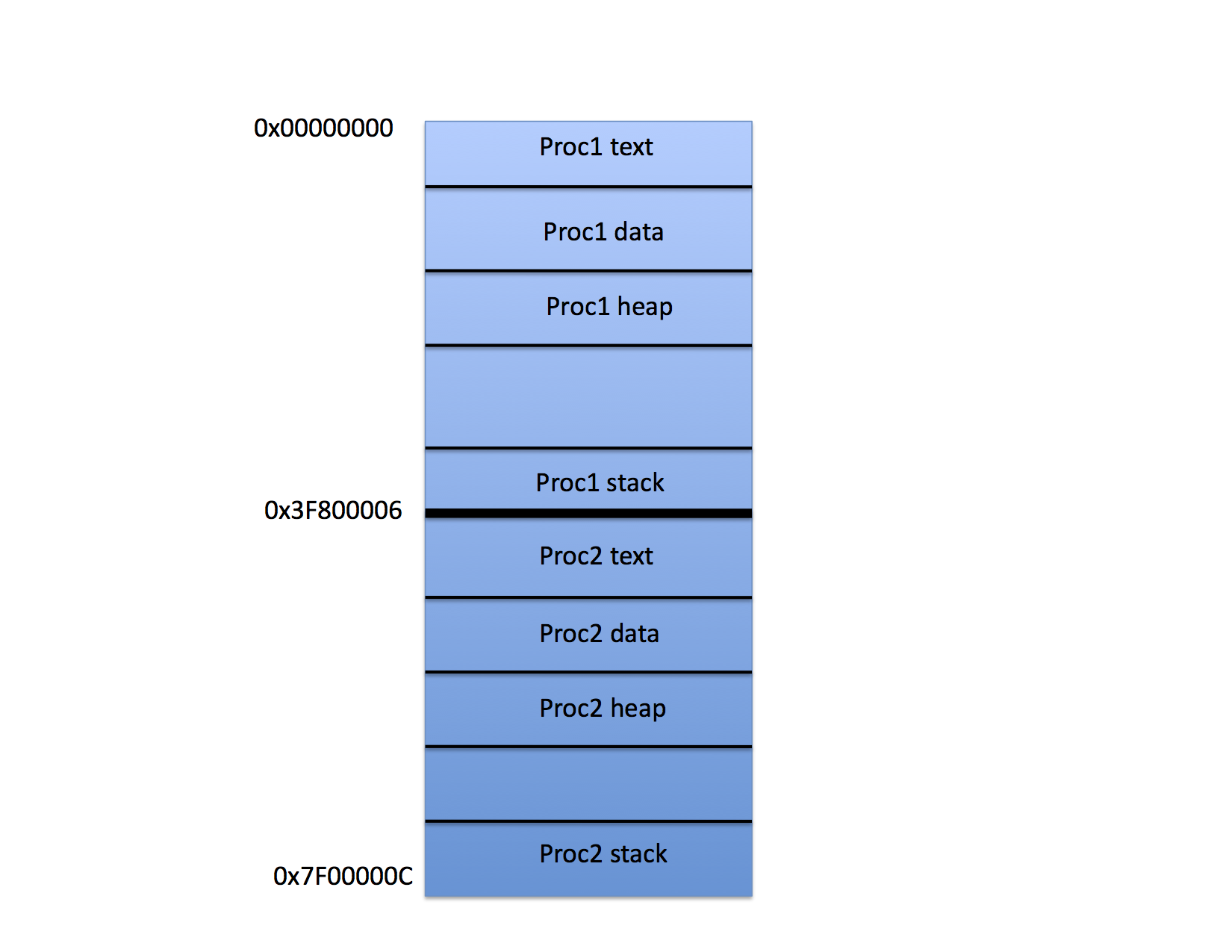
On this figure, Proc1 has been loaded into the top half of the physical memory and Proc 2 into the bottom half. Presumably the OS is prepared to switch back and forth between the two processes using time slicing and context switching.
However notice that if it is physical memory alone, the compiler must “know” where the program will be loaded so that it can adjust the address constants appropriately. The stack pointer isn’t a problem, but the global variables are.
Worse, in this scenario, one program can read and update the variables belonging to the other simply by addressing the memory. For example, if Proc 1 executes the instruction sequence
LD SP, 0x7f00000C
it will suddenly be accessing the stack variables of Proc 2.
Base and Bounds
One simple solution to both problems is for the CPU to include “base and bounds” registers that “fence” memory.
- when the program is loaded, a base register is set to contain the physical address of where the first logical address of the program will be located in memory
- a bounds register is loaded with the physical address of the last (highest addressed) physical memory location that the program can access
- all program instructions refer to logical addresses
- whenever an instruction attempts to access a logical memory location, the hardware automatically
- adds the logical address to the contents of the base register to form the physical address of the access
- compares the physical address to both the base register and the bounds register
- if the physical address is less than the base or greater than the bounds an address out of range exception is generated
- otherwise, the access processed with the new physical address
- OS must ensure that base+bounds pairs for different programs do not overlap
- can also be implemented with a check on the logical bounds (see page 284)
Thus the compiler uses the same address constants for every program it compiles, usually assuming that the program will be loaded at location zero. When the OS loads the program, it sets the base register to the physical address where the program should start and the CPU adds this value to every address that the process uses when it is executing.
For example, in the figure, the base register would be loaded with 0x3f800006 when Proc 2 is running. The compiler, however, would compile Proc 2 as if it were always loaded at location 0x00000000 and the CPU adds the contents of the base register to every attempt to access memory before the access takes place.
Notice that when the CPU switches to run Proc 1 it must change the base register to contain 0x00000000 so that the addresses in Proc 1 are generated correctly. When the CPU switches back to Proc 2 it must reload the correct base address into the base register at context switch time, and so on.
Notice also that it is possible, using this scheme, to switch Proc 1 and Proc 2 in memory. If, say, Proc 1 were written to disk and then Proc 2 were written to disk and then Proc 1 were read from disk, but this time into memory starting at 0x3f800006 it would run just fine as long as the base register were set to 0x3f800006 every time it runs.
The limit register is just like the base register except it indicates the largest address that the process can access. Because it isn’t used to compute the address it is sometimes expressed as a length. That is, the limit register contains the maximum offset (from zero) that any address can take on.
When a process issues a request for memory, then, the address that has been generated by the compiler is first checked against the value in the limit register. If the address is larger than the limit value, the address is not allowed (and a protection fault is generated, typically). otherwise, the address is added to the value in the base register and sent to the memory subsystem of the machine.
Because these operations are done in the CPU hardware they can be implemented to run at machine speed. If the instructions necessary to change the base and limit registers are protected instructions, then only the OS can change them and processes are protected from accessing each other’s memory.
Static versus Dynamic Linking
- static linking: all addresses are resolved before the program is loaded
- dynamic linking: addresses are resolved “on demand”
- when an address exception occurs, the exception handler
- checks the logical address to determine if it refers to a routine or variable that must be dynamically linked from the information kept in a “link table”
- if it is a valid address, the routine is loaded and the memory management state is adjusted
- for example: bounds registers would be incremented to reflect additional code or variable
- instruction causing the exception is restarted
Memory Partitioning
The idea of loading programs that are relocatable at different locations in memory and using the CPU to implement memory protection is called memory partitioning. In the previous example, the memory is divided into two sections (called partitions). A program can run in each partition and when it does the CPU base and limit registers (set only by the OS) implement memory protection.
This type of memory partitioning scheme is called “fixed” partitioning and it was used in some of the early mainframe computers. When the machine is configured, the administrator (or systems programmer) would set the number of partitions that the machine could use and the OS would schedule processes to use them.
Internal Fragmentation
Notice, though, that the scheme can be inefficient with respect to memory usage. If all of the processes are the same and they are written to “take up” the size of a memory partition, then memory is fully utilized. However, that almost certainly is never the case. Instead, small processes that do not require all of the memory in the partition to which they are assigned simply leave that memory idle.
In the Linux example shown above, the space between the heap (which grows toward higher memory addresses) and the stack (which grows toward lower memory addresses) is unused memory. If the text segment is loaded at the lowest address in a partition and the initial SP is set to the highest address in the partition when the process is first loaded, any space between the heap and stack boundaries is idle memory. The process may use it, but it is not available to other processes. Thus a process with a small text, data, heap, and stack still takes up a full partition even if it only uses a small fraction of the available memory space.
This problem is called fragmentation since the memory is divided into fragments (each of which is contiguous) of “used” and “unused” memory. More specifically, when the partitions are fixed in size, the term internal fragmentation is often used to indicate that the fragmentation is internal to the partitions.
Variable Memory Partitions
Notice that a partition is an artificial boundary that is determined by the values of the base and limit registers chosen by the OS. For example, if there are only six different values for the base register that the OS will ever choose, the memory will have seven partitions.
It is possible, however, for the OS to choose different values dynamically as memory demand varies. Because the code is relocatable based on the base and limit registers it can vary the partition boundaries possibly reloading a program into a smaller or larger partition.
For example, when the OS boots, if it runs a single process, that process can be given all of memory. If a second process arrives to be scheduled, the OS can
- stop the first process
- copy all of the processes used memory into half of the memory
- reset the base, limit and SP to reflect the new memory region
- load the new process into the memory that has been freed and set its base, limit and SP accordingly
- start both processes
In practice, this relocating of an existing process is rarely implemented because it is expensive (in terms of overhead) and complex. The process must be stopped and its memory copied. If there is only one CPU in the system, then no other processes can run while this copy takes place. Also notice that the compiler must be very carefully written to not put memory addresses in registers (since some of those addresses, like stack addresses, will change when the process is moved). That is, if the field length shrinks (limit is decremented) the offsets of variables will change. The compiler can ensure that all references are relative to some register that is loaded when the program runs to make the code completely relocatable.
For these reasons the typical implementation would give each process a maximum field length when it was created (usually based on some user input or administrator set parameters). Once a process began executing it would not change its field length. The OS would then assign a base register value when the process runs based on the other processes already running in memory.
For example, consider the three processes that have been loaded into memory as shown in the following figure.
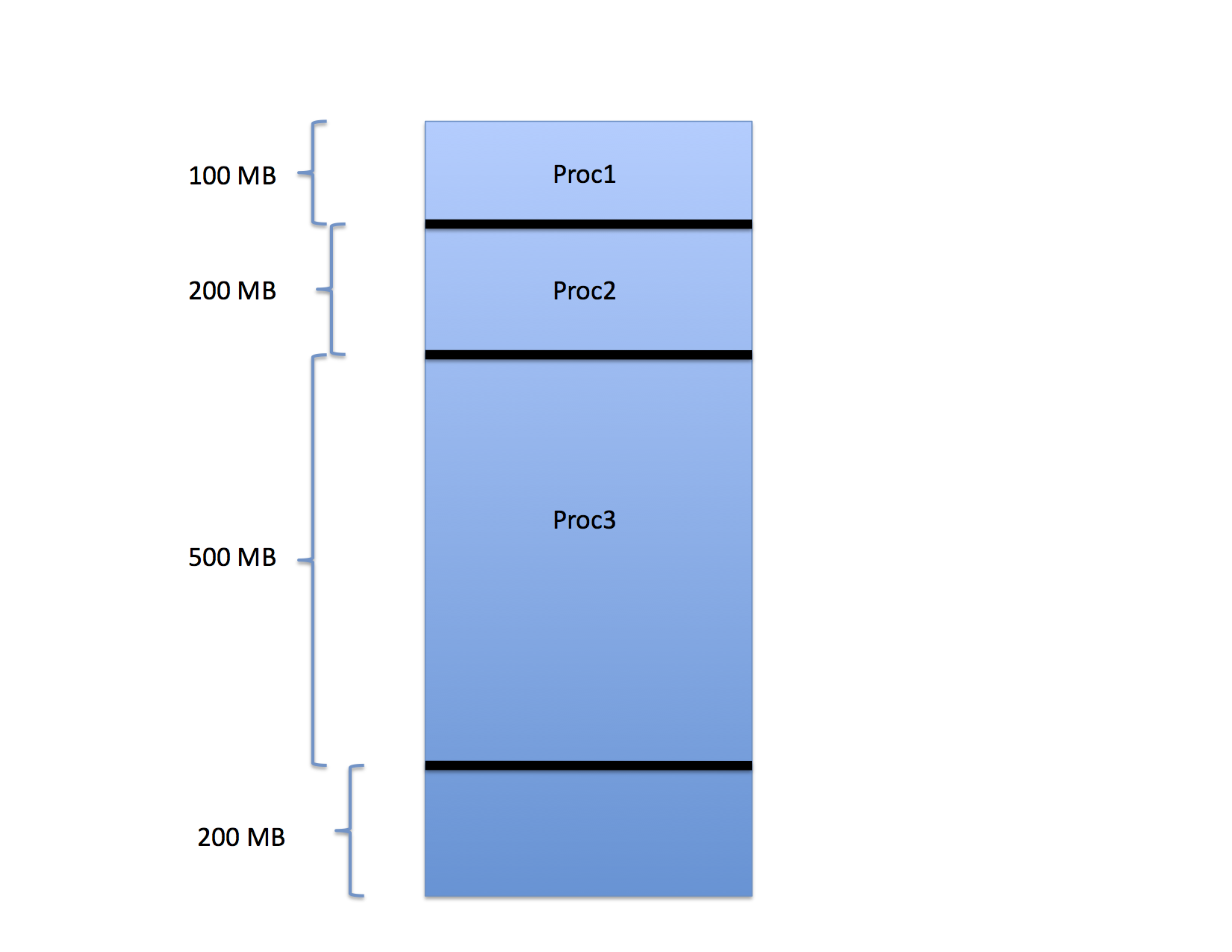
In the figure, Proc1 occupies the first 100 MB of space in a memory that is 1GB is total size. Proc2 occupies the next 200 MB and Proc 3 occupies the 500 MB after that. The last 200 MB are free.
When these processes were loaded, the OS chose the base register value for each so that the processes would pack into memory in this way. That is, the base register value for the next process is the sum of the base and limit values of the one before it. If a fourth process were to arrive, the OS would schedule it to the last 200 MB of memory accordingly.
External Fragmentation
Next, consider what happens if Proc2 finishes execution.
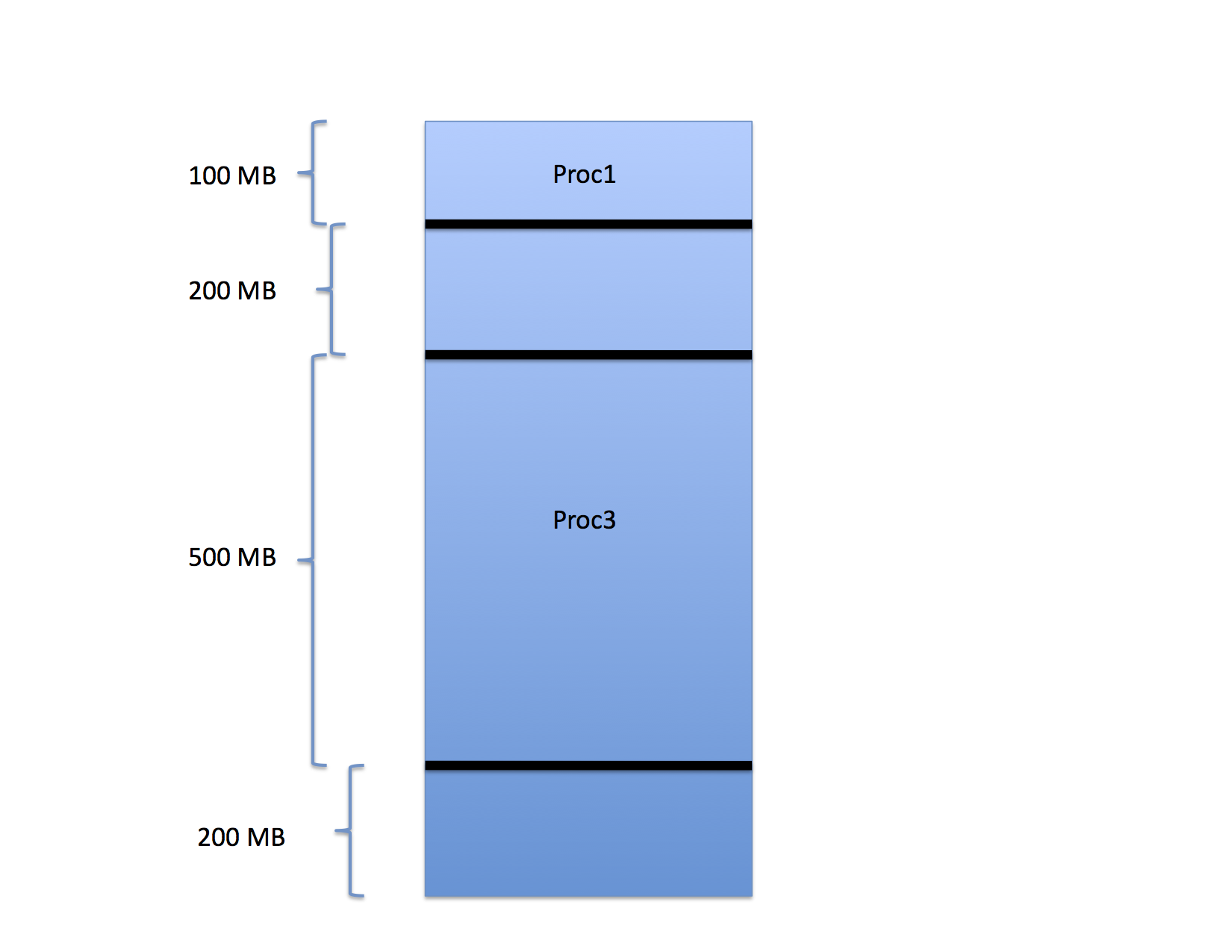
The region freed by Proc2 between Proc1 and Proc3 can now be assigned to a new process as can the free region between the end of Proc3 and the end of memory.
Notice, though, that there are 400 MB free but the largest process that can be run is only 200 MB. What happens if a 300 MB process arrives? It cannot be started even though only 60% of the memory is occupied.
This type of fragmentation is often called external fragmentation because the wasted space occurs outside of each assigned partition.
How Does it Fit?
Notice that the OS has a choice when it goes to assign a newly arrived process that does fit. For example, if a new process that requires 100 MB arrives, the OS can either place it in the hole left by Proc2 or in the hole between the end of Proc3 and the end of memory. Let’s say it chooses the hole left by Proc2:
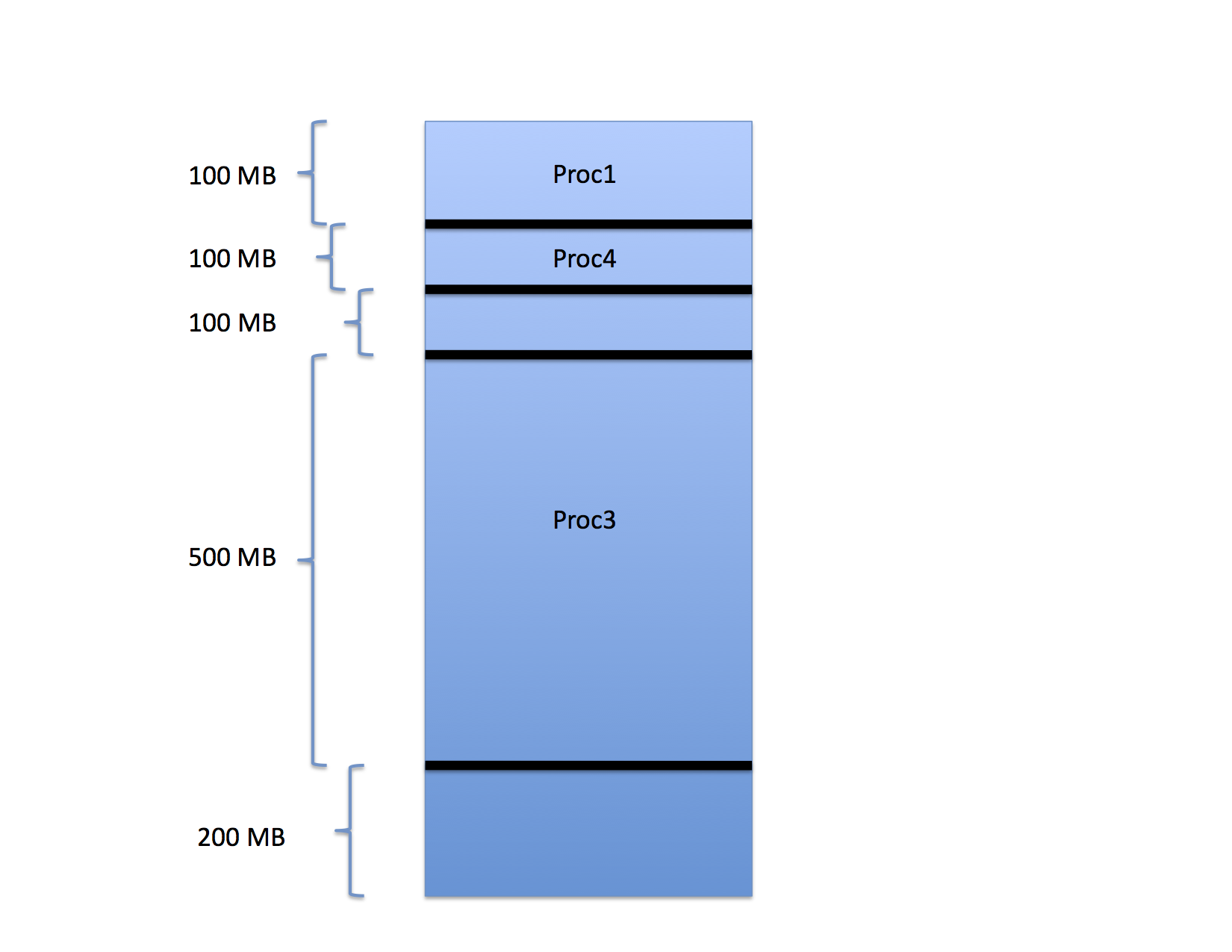
as shown for Proc4.
So far so good, but now consider what happens if the fifth process to arrive requires 75 MB. In which hole should the OS place this job? Generally, there are three options:
- first-fit:starting from one end, choose the first partition in which the process will fit,
- best-fit:scan the entire list of free partitions and choose the one that exceeds the size of the process by the smallest amount (break ties any way you like)
- worst-fit:scan the list of partitions and find the one that exceed the size of the process by the greatest amount (again, break ties in any way)
In this example, if the OS used first-fit (and started from the top of the address space in the figure) it would place the 75 MB job in the hole between the end of Proc4 and the beginning of Proc3 since that would be the first hole it would come to in the list of holes. If the OS used best-fit, it would make the same decision (since 75 MB fits “better” into 100 MB than 200 MB) and if it used worst-fit it would choose the 200 MB hole between the end of Proc3 and the end of memory.
Which is best?
Which is best? That’s a matter of some debate. There has been a great deal of research looking at this question and, curiously, there isn’t a definitive theoretical result. You can argue it pretty much any way you like. Best-fit tends to maximize the number of small holes. Thus if your job size mix doesn’t include a lot of small jobs, it might not be best. Worst-fit tends to maximize the number of big holes. That sounds like a good thing, but in simulation it tends to do worse that best-fit or first-fit. First-fit is fastest (since you don’t need to scan the entire list of free partitions) and it tends to make the hole size tend toward the average. Generally speaking, in the absence of some specific distribution information about sizes, most implementations choose first-fit due to its simplicity. However that is a rule of thumb and not an axiom and there are other allocation schemes one can consider.
Swapping and Backing Store
Memory is memory and bytes are bytes so as long as the OS can copy memory to disk and back again, it is possible for the OS to run more processes than can fit in memory by “parking” some of them on disk and swapping them for running processes periodically. Notice also that if the processes are relocatable in memory, they need not be swapped back into same region of memory when they are reloaded.
To swap a process out, the OS must
- cause the process to stop (usually by taking it off the run queue during an interrupt)
- save off all of the processes CPU state (registers, for the most part)
- find a place on disk to store the memory image of the process and its register state
- copy the memory that the process occupies to disk
- add the partition the process occupied to the list of free partitions
In addition, it is nice if the OS zeros out the memory that the process just vacated so that another processes doesn’t get to see its “secrets” if it is loaded to the same region of memory. This zero fill can be done later just before the new process loads as well.
Similarly, to swap a process in, the OS must
- find a free memory partition large-enough to hold the process
- copy its memory image from disk into the memory partition
- make sure its saved CPU state is available when the process runs again
- put the process on the runnable queue
Thus, as a form of slow motion “time slicing” the OS can multiplex the memory by swapping processes to disk. The disk and copy times are long compared to CPU execution speeds. Thus the interaction between the CPU process scheduler and the memory scheduler must be “tuned.” The typical interaction is to allow the in-memory processes to run for some long period while others wait on disk. As the disk processes “age” their priority for memory goes up (although at a slower rate than the aging rate for processes that are waiting for CPU in a CPU timeslicing context). Eventually, when a disk process has waited long enough, an in-memory process is selected for eviction to make room for the in-coming disk process, and so on.
Notice that the first-fit, best-fit, worst-fit situation pertains to the disk as well. The backing store is usually a fixed region of disk space (larger than the size of main memory) that must be partitioned to hold process images while they are waiting to get back into memory.
Modern operating systems such as Linux use swapping (hence the term “swap space” or “swap partition” that you may have heard in conjunction with configuring a Linux system). As we will see, however, they do so in a slightly different way than we have discussed thus far.
Compacting Memory
Before machines supported “demand paging” (see below) one use for swapping was to “clean” the memory of external fragmentation. If the OS determined that processes were not being accepted because there were too many holes and the holes, if coalesced, would allow more processes to be admitted, one thing it could do was to swap “all” processes out and then swap them back in again, packed one against the other. This form of “defragmentation” was not popular with interactive users, however, since it meant that the OS would need to stop everything until memory could be compacted.
The notion of physical memory partitioning may seem quaint by modern standards. It is efficient with respect to execution speed, however, since the base and limit register accesses are almost trivial in terms of CPU cycles lost to memory protection. So much so that specialized supercomputers like those built by Cray used this scheme for many years.
Demand Paging
Modern systems use a different scheme for memory management, however, that is often referred to as “virtual memory” but which is more properly termed demand paging.
The basic idea is pretty simple. Instead of having a single base and limit register for the entire process (thereby requiring the whole process to be in contiguous memory), the CPU supports the notion of a “map” that automatically converts a relocatable address to a physical memory address. Thus, as is the case with memory partitioning, each process is compiled so that its internal addressing is relative to address 0x00000000 and the hardware maps each address to a physical memory address automatically. In the case of base and limit the mapping is an addition of the value contained in the base base register to the address to provide an address in physical memory.
For demand paging, however, the map is a table in memory that the OS sets up which tells the CPU explicitly where to find a memory reference in physical memory. The OS loads the address of this table into a special CPU register when the process is scheduled and all references to memory made by the process are subjected to the mapping operation by the CPU so that they can be translated into physical addresses.
However, to cut down on the number of entries in the table, individual address are not mapped. Rather, the memory is broken up into pages of a fixed size. All pages are the same size and, for reasons of efficiency, the size needs to be a power of 2.
The Page Table and Address Mapping
The first thing to appreciate about demand paging is the relationship between binary numbers and addresses. An address is really just an offset from zero that refers to a byte in memory that the CPU uses to access that byte.
However, consider the following example address
0x000002D0
This address is 720 in decimal. Let’s look at it in binary, though
0000 0000 0000 0000 0000 0010 1101 0000
So far so good? Okay now think of it this way. Instead of it being the 720th byte in memory, imagine it to be the 208th byte in a 512 byte page that has been mapped to some physical page frame in physical memory. That is, the low-order 9 bits in the address give you an offset from the nearest 512 byte frame in the memory space. Put another way, you can think of an address as being an offset from zero or you can break it up into pages that are powers of two in size, in which case
- the lower order bits give you the offset in the page
- the high order bits give you the page number, in linear order, among all frames
- the boundary between low-order and high-order is the number of bits necessary to express the page size
thus multiplying the page number by the page size and adding the offset gives you the linear address.
For example, if the page size is 512 bytes, then boundary between page number and offset is defined so that the low-order offset is 9 bits since 2^9 is 512.
Page Number | Offset
|
0000 0000 0000 0000 0000 001 | 0 1101 0000
|
|
The left most 23 bits in this address give the page number which, in this example, is 1. The offset is 0xD0 which, in decimal, is 208. Thus to compute the linear address we can multiply the page number by the page size and add the offset:
Page Number Page Size Offset
----------------------------------
1 x 512 + 208 == 720
Why does this matter? Because it allows us to build a table that will map pages of address space to arbitrary pages in physical memory based on page number. An address translation requires the following steps be executed by the CPU each time an address is referenced by a process.
- the page number is extracted from the high order bits of the address
- the number is used as an index into a page table for the process that contains the page number of the page in physical memory
- the physical page number is multiplied by the page size and added to the offset
- the CPU uses this new quantity and the physical address
From here on in, we’ll use the terms
- page number to refer to the page number in the process’ address space
- frame number to refer to the page number in physical memory space
The page table maps page numbers to frame numbers. The page number is an index into the table and the entry contains the frame number.
Each entry in the page table actually contains more than the frame number. In particular each page table entry contains
- frame number
- status bits
- valid: contains valid data, but backing store is consistent
- modified: contains valid data and backing store is inconsistent
- referenced: used to determine run set (see
- protection bits
- usually 2 indicating Read and Write permissionsbelow)
The page table is a one-dimensional array of page table entries, indexed by page number, containing the following information:
-----------------------------------------------------------------
| Physical Frame # | valid | modified | referenced | protection |
-----------------------------------------------------------------
Ignoring these additional bits for a minute, the following figure shows a possible page mapping
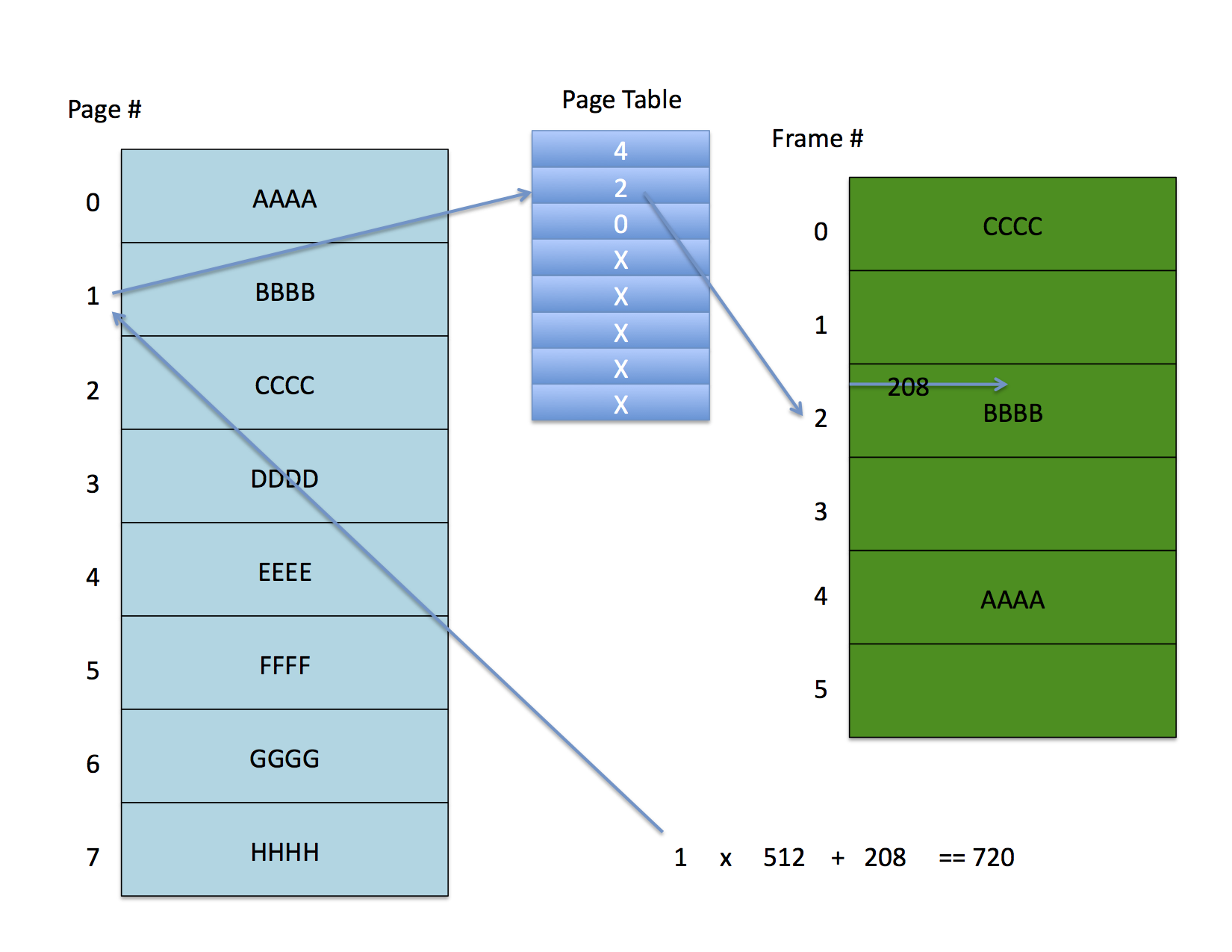
The address space on the left is partially mapped to the physical memory on the right. Address 720 with a 512 byte page size indexes to the second entry (counting from zero) in the page table. This entry contains frame number 2 which, when multiplied by the page size and added to the 208 byte offset yields the physical address.
It is important to understand that this address translation is done by the CPU (or more properly by the MMU – memory management unit) on every memory access – it cannot be avoided. Thus as long as the OS controls the set up of the page table processes cannot access each other’s memory.
Further, each process needs its own page table. It is possible for processes to share memory, however, if the same frame number is listed in each sharing process’ page table. Notice also that if they were to share memory, they don’t need it to have the same address in their respective memory spaces.
For example, page 7 in process 1 might refer to frame 5 which is being shared with process 2 which has it mapped to page 10. In this example, the 8th entry of process 1’s page table would contain 5 and the 11th entry in process 2’s page table would also contain 5 since they are both mapping frame 5.
The Details
The hardware specifies what the format of this entry is exactly so it will change from platform to platform, but a machine that supports full demand paging will contain these elements. Note also, that the figure is not drawn to scale. The valid, modified, and referenced fields are typically bit fields, and the protection field is typically two bits wide.
The protection field usually contains two bits that enable four kinds of access:
- none: no access permitted
- read only: process may read but not write
- write only: process may write but not read
- read/write: process may read and modify the page
We won’t dwell on the protection bits much from here on out. The important thing to know is that when an access that violates the bits that are enabled occurs, the hardware throws a protection fault in response. For example, the read only bit will be set for all pages in the text segment of a Unix program and a protection fault occurs if you try to write those pages. Similarly, a no access page may be put between the stack and heap to allow the process to fail gracefully if you over-write either. This page is called a red page.
For what remains, recall that the page number is an index into a table of these entries from which the frame number is recovered.
Backing Store: Disk Block Descriptor Table
Notice that the OS can use disk as a backing store to page frames out of physical memory. However, because processes usually exhibit spatial locality, only a subset of pages out of a process’ full page set need to be present most of the time. Thus, the OS can “park” individual pages that haven’t been accessed in a while on disk.
To figure out where the data resides on disk, the system maintains a second table, also indexed by page number, that contains the following entries.
-------------------------------------------------
| swap device # | disk block # | swap file type |
-------------------------------------------------
Don’t worry about the type. Just notice that what the kernel is doing here is storing the disk location where the backing store for a given page is located. Logically, these two entries are part of the sample table entry. they are typically implemented as separate tables, however, since the hardware will want pages tables to look a certain way, but backing store descriptors are completely up to the OS to define.
Frame Table
The system also maintains a table of records that describe what each frame of memory is currently storing. In each record, the kernel stores
--------------------------------------------------
| ref count | swap device # | disk block # | PTE |
--------------------------------------------------
for each frame in the system. There are also some other fields that have to to with allocating and freeing frames but we won’t go into the details. Suffice to say that the OS need to be able to sweep through the frames that are currently occupied in memory every once and a while and knowing where the frame is paged on memory is handy.
In summary,
- each page in a program must be loaded into a memory frame before the CPU can access it
- each page in a program has a “shadow” copy on the swap device at some disk block number.
- when a page is loaded into a frame
- a free frame is allocated (not described yet)
- the page is fetched from the disk block location
- the page table entry is updated with the frame number
- the valid bit is set to indicate that the in-memory copy is valid with respect to the copy on disk
- the disk block address from the block descriptor table for the process is copied into the frame table entry for the frame
- a pointer to the page table entry is put in the frame table entry
- the reference count for the frame is incremented
Note that the frame table is shared among all processes executing at the same time. The OS uses it to identify when frames are free and, when they are not free, which page table entry corresponds to the page that occupies a Frame. For example, the following figure shows two processes that each have their first three pages mapped to frames.
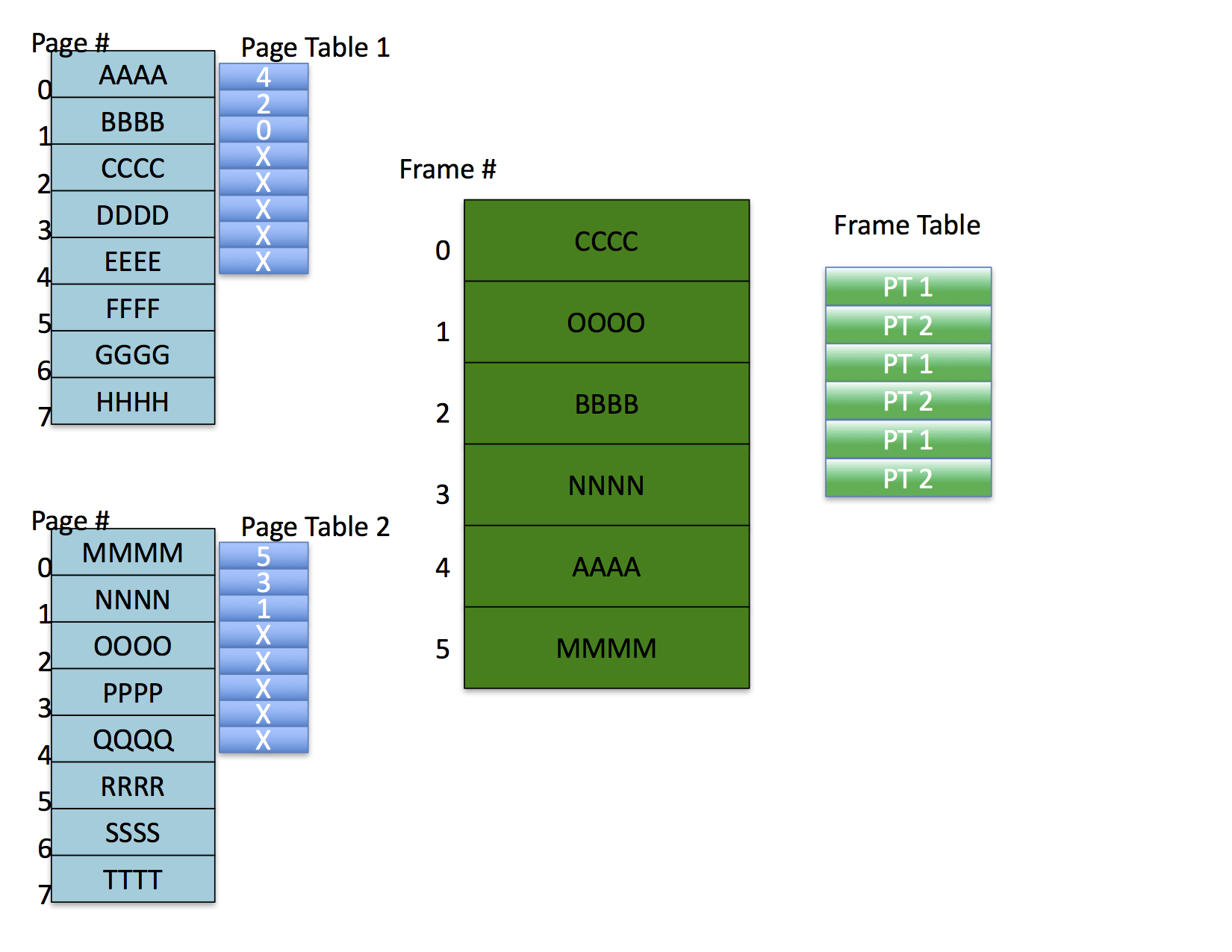
Each frame table entry for memory indicates which page table entry corresponds to the mapped page in the frame.
Notice also that, in this example, the OS has allocated pages to frames such that there are no shared frames. It is possible, however, for processes to share memory under this scheme by having different pages mapped to the same frame. In this case, the frame table requires a list of page table entries for the page tables that map the frame (not shown in the figure).
Page Faults
We now have enough information to understand exactly what a page fault is. Every time the CPU issues a memory reference (sends an address across the address bus)
- the hardware masks off the page # and indexes into the page table for the process
- the valid bit in the page table entry for the page is checked (by hardware)
- if the valid bit is set, the frame number for the physical frame is retrieved, multiplied by the page size, and added to the offset in the address to form the physical address. No page fault is generated.
- if the valid bit is not set, the CPU throws page fault exception that the operating system must catch.
- the page fault exception handler must
- allocate a free frame
- fetch the page from the location specified in the disk block descriptor table and load it into the frame
- update the frame table entry (as described above)
- update the page table entry (as described above)
- restart the process so that it reissues the faulting instruction
In the previous figure, the entries marked X in the page table are not valid entries. In the page table entry itself, the valid bit would be set to zero to indicate that the entry does not contain a valid mapping.
When the CPU does the address translation, and it goes to fetch the frame number from the page table entry, it check the valid bit. If the valid bit is clear, the CPU throws a page fault which traps into the OS. The OS must fine a free frame, load the frame with the data from the address space into the frame, and restart the process at the place where the fault occurred, load the frame with the data from the address space into the frame, and restart the process at the place where the fault occurred.
Initiating an Address Space
Okay – at this point, you should be able to visualize how a program address space is initiated (although we haven’t talked about all of the mechanisms in detail yet). To start a program, the OS must
- allocate swap space: space on the backing store that can hold images of the pages in memory
- allocate a page table for all of the pages a program might use. This table must be contiguous since the hardware indexes into it.
- allocate a disk block descriptor table to hold the backing store information
- copy each page of the program into the swap space noting the disk block and swap device number of the page in the appropriate disk block descriptor table entry
- set all of the valid bits in the page table to be zero
- run the program
The very first fetch of an instruction will cause a page fault to occur since it will be attempting to read page 0. Since the valid bit is clear, the OS will take a page fault exception immediately, go to the disk block descriptor entry for page 0, find the disk block number, get a free frame, load the page into the frame, update the frame table entry with the pointer to the page table entry, update the page table entry with the frame number, set the valid bit to 1, and restart the faulting instruction. When the programs runs onto page 1, or jump to another page, it will be faulted in accordingly.
The only two pieces you are missing, before understanding exactly how this works concern how frames are allocated and deallocated, and how swap space (backing store) is managed. We won’t discuss these two issues in detail since they vary considerably from system to system. Each OS includes a swap space manager that can allocate and deallocate frame sized regions of disk space from the swap partition. Most OSs also maintain an internal “cache” of pages that have been used recently but are not allocated to a process. This page cache gets searched (efficiently) before the OS goes to disk to get a page.
Dirty Pages
So far, we have discussed how frames are allocated and freed without much regard to what happens when the in-memory copy is written, making it inconsistent with the disk copy. When a program modifies a variable (either a global variable, a variable on the heap, or a variable on the stack) the page must be in a frame, and the valid bit must be set (or a page fault will occur), and when the modification occurs, the hardware sets the modified bit in the page table entry to indicate that the in-memory copy is now different (and more current) than the disk copy. It does NOT go out to disk at that time and update the disk copy. Why? Because your program is constantly modifying variables. If you had to way for a page to be flushed to disk, every time you made a simple assignment statement in your program, your program would be very very slow.
The term “dirty” is sometimes used to refer to a page that has been modified in memory, and the modified bit is occasionally termed “the dirty bit.” Notice that a dirty page is always more current than the backing store copy. Thus, to “clean” a page, the copy that is in memory must be “flushed” back to backing store, updating the backing store copy to make it consistent with the memory copy.
More on Freeing Frames
What happens when a page fault occurs, but there are no free frames? The OS cannot simply steal a frame from a running program. Or can it?
What would happen if the OS, when confronted with no free frames, simply chose a frame that was being used by a program, cleared the valid in the program’s page table entry and allocated the frame to the new program? If the program that originally owned the frame were using it, it would immediately take a page fault (as soon as it ran again) and the OS would steal another frame. It turns out that this condition occurs (in a slightly different form) and it is called thrashing. We’ll discuss that in a minute, but the remarkable thing to notice here is that the OS can simply steal frames that are in use from other programs and those programs will continue to run (albeit more slowly since they are page faulting a great deal).
What actually happens has to do with locality of page references. It turns out that a large number of studies show that program access “sets” of pages for a good long while before they move on to other “sets.” The set of pages that a program is bashing through repeatedly at any given time is called the programs run set. Very few programs have run sets that include all of the pages in the program. As a result, a program will fault in a run set and then stay within that set for a period of time before transitioning to another run set. Many studies have exposed this phenomenon and almost all VM systems exploit it. The idea, then, is to try and get the OS to steal frames from running programs that are no longer part of a run set. Since they aren’t part of a run set the program from which the frames are stolen will not immediately fault them back in.
Identifying Run Sets and Page Stealing
How, then, can the OS determine a program’s run set? The common methodology uses the referenced bit the page table entry that we have not heretofore discussed and a another special thread called the page stealer. Could I make this up? I ask you.
Here is the deal. First, every time a reference is made to a page (with read or write) the hardware sets the referenced bit in the page table entry. Every time.
The page stealer wakes up every now and then (we’ll talk about when in a minute) and looks through all of the frames in the frame table. If the referenced bit is set, the page stealer assumes that the page has been referenced since the last time it was checked and, thus, is part of some processes run set. It clears the bit and moves on. If it comes across a page that has the referenced bit clear, the page stealer assumes that the has not been referenced recently, is not part of a run set, and is eligible to be stolen.
The actual stealing algorithms are widely varied as Unix designers seem to think that the way in which pages are stolen makes a tremendous performance difference. It might, but I’ve never heard of page stealing as being a critical performance issue. Still one methodology that gets discussed a great deal is called the clock algorithm. Again – there are several variants. We’ll just talk about the basics.
The Clock Algorithm
If a particular OS uses the clock algorithm for page stealing, the page stealer wakes up when one of two events occurs:
- a periodic timer has expired
- the number of free pages in the system falls below a “low-water mark” indicating that the system is running short of free pages.
Both the timer interval and the low-water mark can be set with the kernel is configured allowing a certain amount of “tuning.”
The page stealer then maintains two “hands” – one “hand” points to the last place the page stealer looked in the frame table when it ran last. The other “hand” points to the last place it started from. When the page stealer runs, it sweeps through the frame table between where it started last and where it ended last to see if any of the referenced bits are set.
- if the reference count is zero, or the valid bit is clear, the frame is already free and the page is skipped
- if the referenced bit is set and the valid bit is set, the page is part of a run set. The referenced bit it is cleared and the frame is skipped.
- otherwise, if the referenced bit is clear, valid bit is set, but the modified bit is clear, the page is clean and can be stolen. The page stealer sets the reference count to zero and puts the page on the free list, but it leaves the rest of the page intact. Notice that if the system is implementing page caching, and this page really is part of a run set (i.e. the page stealer was just a little too eager), a page fault will occur when the page is next referenced, and the page fault handler will most likely find the page on the free list. Thus, the cost of being “wrong” about a page being in a run set is most likely to be an extra page fault, but not an extra disk access.
- otherwise if the referenced bit is clear, valid bit is set, and the modified bit is set, the page is not part of a run set, but it is dirty. The page stealer schedules the frame for cleaning by putting it on the page out queue and waking the page out thread. It does not steal the page, though, but rather waits until the next pass to see if it is unreferenced and clean before it is stolen.
Here is a brief table summarizing this mess. For each frame between the starting point and the ending point (the two “hands”)
v = 0 or ref cnt = 0 : page is free so skip it
v = 1, r = 1 : page is busy. clear and skip
v = 1, r = 0, m = 0 : page is clean and unreferenced. steal
v = 1, r = 0, m = 1 : page is dirty and unreferenced
schedule cleaning and skip
Once the page stealer has run this algorithm for all of the pages between its start point and end point, it must move these points in the frame table. it does so by changing the new start point to be the old end point (wrapping around the end of the frame table if need be) and then it walks forward some specified number of frames (again wrapping if needed) clearing the referenced bit for each frame. These are the new start and end points (“hands”) for the next time it wakes up.
It is called the clock algorithm because you can think of the frame table as being circular (due to the wrap around) and because start and end pointers work their way around the circle.
Variations on this theme include “aging counters” that determine run set membership and the way in which dirty pages are handled. I’ll just briefly mention two such variations, but each Unix implementation seems to have its own.
If you think about it for a minute, you can convince yourself that the clock algorithm is an attempt to implement a Least Recently Used (LRU) policy as a way of taking advantage of spatial and temporal locality. The most straight-forward way to implement LRU, though, is to use a time stamp for each reference. The cost, of course, would be in hardware since a time stamp value would need to be written in the page table entry each time a reference occurred. Some systems, however, time stamp each page’s examination by the page stealer using a counter. Every time the page stealer examines a page and find it is a “stealable” state, it bumps a counter and only steals the page after a specified number of examinations.
The other variation has to do with the treatment of dirty pages. SunOS versions 2.X and 3.X (Solaris is essentially SunOS version 4.X and higher) had two low-water marks: one for stealing clean pages and a “oh oh” mode when all stealable pages would be annexed. In the first mode, when the system ran a little short of pages, it would run the clock algorithm as described. If that didn’t free enough pages, or if the free page count got really low, it would block the owners of dirty pages while they were being cleaned to try and get more usable on the free list before things got hot again. Usually, if the kernel found itself this short-handed, the system would thrash.
Thrashing
You’ll notice that demand paging is really a “race” between processes that are touching pages (thereby using valuable page frames) and the page stealer that is attempting to keep the frames free. Under normal conditions, the run set of each running process is small enough to fit into memory, and the LRU approximation algorithm (e.g. the clock algorithm or one of its variants) is able to correctly identify each run set. If enough processes are running to make the run sets larger, in total, than the number of physical memory frames, then when a page is stolen, it will immediately fault back in (since it will be part of some run set). This condition is termed thrashing and it can be detected by monitoring the page in and page out rates of the system. Try running the Unix utility vmstat (after consulting the man page for details on its function). Among other valuable pieces of information, it typically includes paging rates. No Unix systems that I know of automatically throttle process creations as a result of paging activity, but the information is typically provided by a utility such as vmstat so that administrators can determine when thrashing takes place.
Swapping and Paging Together
Okay – at this point you have a fairly clear picture of all of the mechanisms that must interplay in order to make demand paging work. The concept is deceptively simple, but the implementation obviously involves considerable mechanism. One last mechanism we must talk about (and then we are done) is the process known as swapping.
As mentioned about in the discussion of the clock algorithm, the kernel maintains a count of free pages with the frame table and a low-water mark to indicate when page stealing should occur. A second method that the kernel uses to try and free up frames is to send to the swap device all of the frames associated with a given process, thereby putting them on the free list. Thus, the kernel maintains a swap out thread whose job it is to evict an entire job from memory, when there is a memory shortfall.
Again, your mileage may vary, but the basic idea is for the page stealer to try and do its work and, after making a complete sweep of memory, if there is still not enough free frames, for the page stealer to wake the swap out thread. The swap out thread chooses a job (based on the size of the job and how long it has run) and goes through its entire page table. It invalidates and frees any pages that have the valid bit set, but the modified bit clear, it schedules the valid and modified pages for disk write, and it sets the execution priority of the process to zero (or takes it off the run queue entirely) for a specified period of time. The idea is to pick a large, and old process (one that has received a lot of time already) and “park” it in swap space for a while. By doing so, and freeing all of its frames, the theory goes, a bunch of smaller jobs (which are probably interactive anyway) can get in and run. Also, the free frames might relieve paging pressure so that the unswapped jobs can complete, leaving more memory for the swapped job.
After a suitable interval (OS dependent, of course) the swapped job is put back in the run queue and allowed to fault its pages back in. Sometimes it is given extra time slices as well on the theory that it does not good to let it fault its pages in only to be selected again by the swap out thread for swapping.
And that’s it.
By way of a short summary, here are the highlights for virtual memory:
- there is page table entry for each process page. It contains
- a frame number
- valid, modified, and referenced bits
- there is a block descriptor table entry for each page in a process that contains
- the the swap device number (indicating which swap partition)
- the block number on this device for the page
- some type information indicating if the current page is in the original disk image on on the swap partition
- there is a frame table entry for every physical frame in the system that contains
- a reference count for the frame
- the swap device number for the page contained in the frame
- the block number for the page in the frame
- a pointer to the PTE (or list of PTEs) for the page in the frame
- pointers for the free list/free hash tables
- there is an on-core swap map that indicates which blocks on the swap devices are free and which ones are busy
- processes fault pages in by accessing them.
- reading or writing a page causes a page fault after which the valid bit is set
- any write to a page that changes its contents from the one in swap space sets the modified bit
- any read or write to a page (causing a page fault or not) sets the referenced bit
- all bit setting is done by hardware, typically
- page faults require that frames be allocated
- frames are deallocated when
- the process terminates, giving up its pages
- the page stealer determines that they are not part of a current run set
- the swap out thread sends an entire process to swap space
- pages can be reclaimed from the free list (page cache) if they are still valid
- data structure like the buffer cache (with a hash table) is employed to make look up faster
- when a page is dirty and heading to disk, care must be taken to prevent the process from being scheduled and attempting to access the page. Thus the page out thread and the process have a race condition that must be managed.
Issues with Demand Paging
There are a few points of concern for demand paging. First, noticed that in the example we have presented, page-mapped memory halves the effective memory bandwidth. Why? Because every time the CPU translates an address it needs to go to memory twice: once for the page table entry and once for the memory access itself.
The solution to this problem is to rely on locality and to add a cache of page table mappings to the CPU called a translation lookaside buffer or TLB.
The TLB is usually implemented as a fast associative memory in the CPU or MMU. When the OS successfully maps a page number to a frame number it puts this mapping the TLB. The TLB is checked each time an address translation is performed and if it contains the mapping, the table look up is not performed.
Thus the true performance of the memory system depends on the size of the machine’s TLB and the degree to which the workload displays spatial locality. Notice also that the TLB is per CPU. Thus when a process context switch takes place, it must typically be flushed of entries so that an new process doesn’t get access to the old process’ memory frames.
Secondly, notice that in the example page table memory is not paged. Thus it must be resident and there must be one for each running process. How much memory do the pages tables take up?
- page table can be huge and must be contiguous
- 512 byte pages => offset is 9 bits
- 32-bit address => page number is 23 bits => 8388608 page table entries
- if page table entry is an int => 33554432 (32 MB) page tables
- each process, then, need a 32MB contiguous region in the kernel => kernel is at least 32MB in size
- larger pages => more internal fragmentation, but smaller pages tables
- what if address space is 64 bits?
Segmentation
The first, and oldest way to deal with this issue is to segment the address space so that each segment can have its own (smaller) page table. For example, as long as a process is not allowed to map its entire address space, a Linux process really only need two segments: one for the test, data, and heap and another for the stack. Then, the “top” segment (text, data, heap) have a page table that is big enough to map the largest allowable heap address (the largest address that the process will be able to allocate to the heap). Similarly the bottom segment is for the stack and mapps the lowest address that the stack pointer can take on. If the stack is allow to meet the heap, then there is no savings of page table space but if the stack and heap boundaries are fixed, then the total space can be smaller. Each segment, however, requires its own page table resister which must be set for by the OS and the hardware determines which one to use based on which segment is being accessed.
For example, let’s imagine that we have a 64-bit address space so that a full page table is not possible. If we assume that the page size is still 512 bits, and page table entry is 4 bytes, and there are two segments for the program (a top and bottom segment) and that we believe that largest a stack will ever get is 16 megabytes, but the test+data+heap could be 1 GB, then the sizes look like
- top segment == 2^21 bits of page space x 4 bytes per page table entry == 8 megabytes of page table
-
bottom (or stack) segment == 2^15 bits of page space x 4 bytes per page table entry == 128 kilobytes of page table space
Hierarchical Page Table
another page table
| 10 bits top level | 44 bits mid-level | 10 bits of offset | -------------------------------------------------------------address
At the next level there are 44 bits of address space which might look like it is a problem, but actually is not if the OS defines a maximum size for test+data+heap and stack. That is, the top level entry points a page table for the text+data+heap that can be at most 44 bits in size, but could be restricted to be less (say 32 bits in size or 4GB). Similarly the last entry in the top level points to the stack’s page table and it could be similarly restricted. By breaking the address space up and not full mapping the regions, you can map a very large address space without having to create a single contiguous page table.
The disadvantage is that each memory reference must access page table memory multiple times. This process of following a memory reference down through a hierarchical page table is called “walking the page table” and it is a very expensive operation. The hope is that these page table walks are made infrequent by the effectiveness of the TLB.
Inverted Page Table
- one physical frame table for all of memory
- entry stores pid and logical page number of the page that is mapped there
- frame table is searched for (pid,page number) pair on each ref
- offset into frame table gives frame number of physical address when matched (see figure 9.15, page 301)
- advantage is that the frame table need only be big enough to map physical memory of machine
- disadvantage is that table must be searched on every access
- hashing
- better hope the TLB is working
- UltraSPARC and PowerPC both support – need I say more?
- one physical frame table for all of memory
Comments