File System
The Unix File System
I’m not particularly fond of Chapters 11 and 12 in S & G, so I’m augmenting them with musings concerning the Unix file system. The primary reference is “The Design of the Unix Operating System” by Maurice Bach, Chapter 4, but almost any book on Unix internals will contain this information.
What is a Unix file?
- abstraction: sequential stream of bytes
- system calls: read(), write(), open(), close(), seek()
Problem: disks are organized as collections of “blocks”
- a disk address is some kind of tuple
- track/sector
- cylinder/platter/sector
- all Unix disk-drivers translate disk addresses to logical block numbers (1..n)
- through the block driver interface you can request block “k” and the driver will convert that to a track/sector tuple.
What should the kernal do?
- The kernel must be able to translate user-process system calls (which refer to a file as a sequence of bytes) to logical block numbers which are then translated into disk addresses by the individual disk driver.
The inode
- maps individual byte addresses relative to the beginning of the file to logical block numbers for a particular disk
- holds permission information for the file, whether the file is a regular file, a directory, a “special” file, and the current file size
--------------------------------
| block # |
--------------------------------
| block # |
--------------------------------
| block # |
--------------------------------
| block # |
--------------------------------
| block # |
--------------------------------
| block # |
--------------------------------
| block # |
--------------------------------
| block # |
--------------------------------
| block # |
--------------------------------
| permissions, ownership, |
| current file size, file |
| type |
--------------------------------
- blocks are a single, fixed size
- table index corresponds to logical position in the file,
block offset in file
--------------------------------
| block 34 | 0
--------------------------------
| block 722 | 1
--------------------------------
| block 1072 | 2
--------------------------------
| block 6 | 3
--------------------------------
| block 377 | 4
--------------------------------
| block 771 | 5
--------------------------------
| block 7 | 6
--------------------------------
| block 83 | 7
--------------------------------
| block 212 | 8
--------------------------------
| block 433 | 9
--------------------------------
| block 812 | single
--------------------------------
| block 96 | double
--------------------------------
| block 531 | triple
--------------------------------
| permissions, ownership, etc |
--------------------------------
-
the above example defines a file. If blocks are 4096 bytes long, the 11033rd byte in the file is found by first calculating the logical offset (in blocks) from the beginning of the file as
11033 / 4096 = 2
At table entry 2 (block offset 2) we find logical disk block number 1072. The byte offset within disk block 1072 is
11033 % 4096 = 2841
So given the inode shown above, the 11033rd byte of the file is byte 2841 of block 1072 on the disk from whence this inode is allocated.
-
latter table slots (single, double, triple in the figure) refer to single-, double-, and triple-levels of indirection.
-
the number of direct, single, double, and triple slots in each inode are implementation specific. However, given these numbers, the block size, and the size of a block number, it is possible to calculate how large the largest file that can be represented is. For example,
assume block number = 4 bytes block size = 4096 bytes # direct blocks = 10 # single indirect blocks = 1 # double indirect blocks = 1 # triple indirect blocks = 1 implies (10) directly accessible blocks + (4096 / 4) single indirectly addressable blocks + (4096 / 4)^2 double indirectly addressable blocks + (4096 / 4)^3 triple indirectly addressable blocks = 1,074,791,434 addressable blocks * 4096 bytes/block = 4,402,345,713,664 addressable bytes within a single file
The file system
- a file system consists of a
- superblock
- a collection of inodes
- a collection of data blocks allocated on a disk
-
when a file system is configured, the number of inodes that will be available for files and the number of data blocks (presumably the (disk size) - (the number of inodes) - 1 for the superblock) are specified.
- inodes on disk are
- logically contiguous on disk so the inode number (the logical offset from the beginning of the inode region) identifies, uniquely, an inode.
- marked with a free/used flag
- the superblock keeps the starting block address of the
inode region and a bit map of free/used data blocks
- if the superblock becomes corrupted, however, but the inode region is known, a program can chase all block numbers are re-create the superblock (see fsck)
Directories, Path Names, and Mount Points
-
a directory is a file that contains string-inode number pairs only
-
by knowing the inode number and the file system (identified by the device number on which the file system resides) in which that inode resides, the kernel can locate the file to which that inode refers
-
for example, assume that a directory contains the following 5 entries
"." : 147 ".." : 91 "cat" : 133 "dog" : 211 "fish" : 12the file "cat" is defined by the 133 inode within the file system in which it resides. The superblock for that file system contains the starting logical block address for the inode region, so the kernel can translate inode number 133 into a logical disk address which can then be read into memory for access. -
a path name is a chain of directory entries or a chain of directory entries followed by a non-directory file. For example
/cs/faculty/rich/cat where "cat" is not a directory, refers to four directories: "/", "/cs", "/cs/faculty" and "/cs/faculty/rich". Assume that they are all on the same file system. Then, each directory has an inode number and "cat" has an inode number. The kernel maintains a table of mounted file systems that contains the superblock for each, and each "root" inode number. -
To find /cs/faculty/rich/cat, the kernel first locates the inode number for “/”, loads the data blocks for that directory into memory, and searches for them linearly looking for the string “cs”. Say the root directory looks like
"." : 0 ".." : 0 "usr" : 1021 "green" : 777 "cs" : 3355 "tmp" : 23 -
the kernel locates “cs” in the directory and reads out 3355 as its inode number. It then goes back to the file system and reads the file (a directory in this case) corresponding to inode number 3355. The process recurses until a non-directory file is located (the file type is kept in the inode).
The Buffer Cache
- inodes and disk blocks are cached in memory
- doubley-threaded list (hash and link lists)
- one buffer cache per configured file system
- hash table is used to look up block numbers
- free list is used to locate free blocks
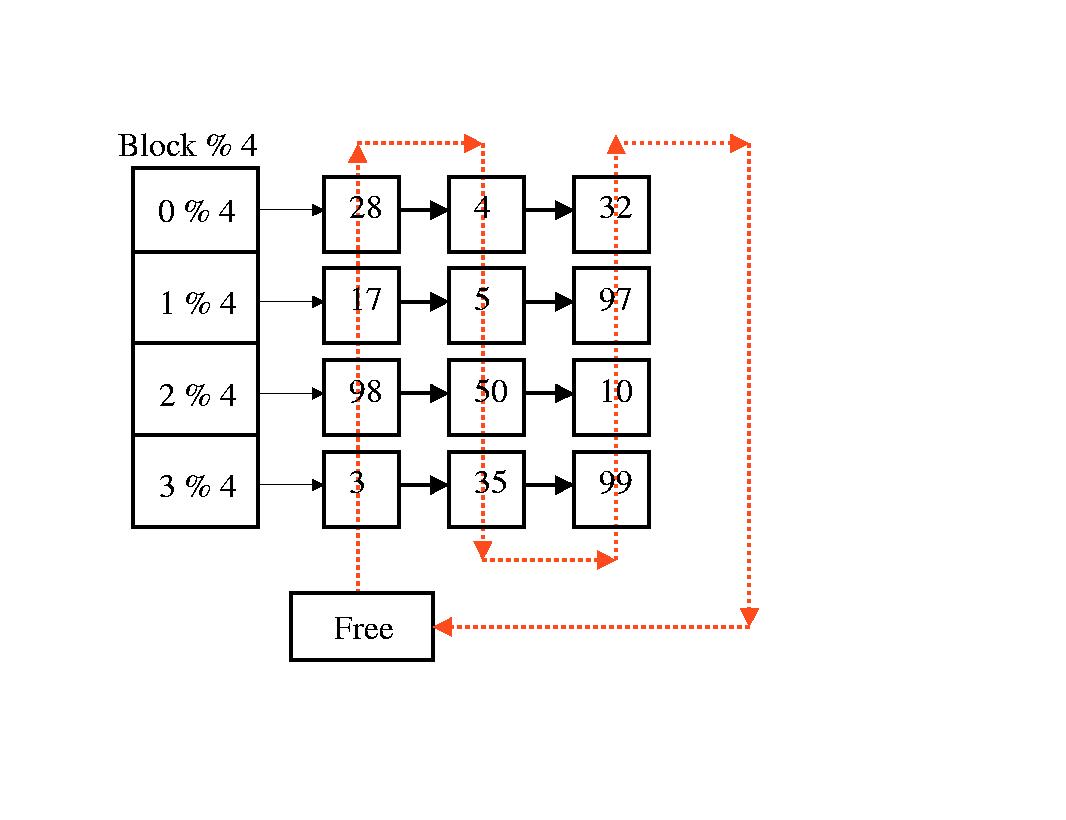
- when a logical block number is requested from disk the hash is consulted to determine if a copy is already available
- while buffer is in use, it is taken off the free list
- when process is finished with buffer, it is returned to the end of the free list
- when a new buffer is required it is taken from the beginning of the free list (LRU)
- if the buffer has been modified, it is scheduled for write-back (dirty bits)
File Decsriptors, Open File Table, Inode Table
- each PCB has a table of file descriptor pointers
- each file descriptor pointer points to an open file table
entry containing
- reference count
- offset
- inode table index
- each inode for an open file is stored in an “in-core” inode table entry with a reference count
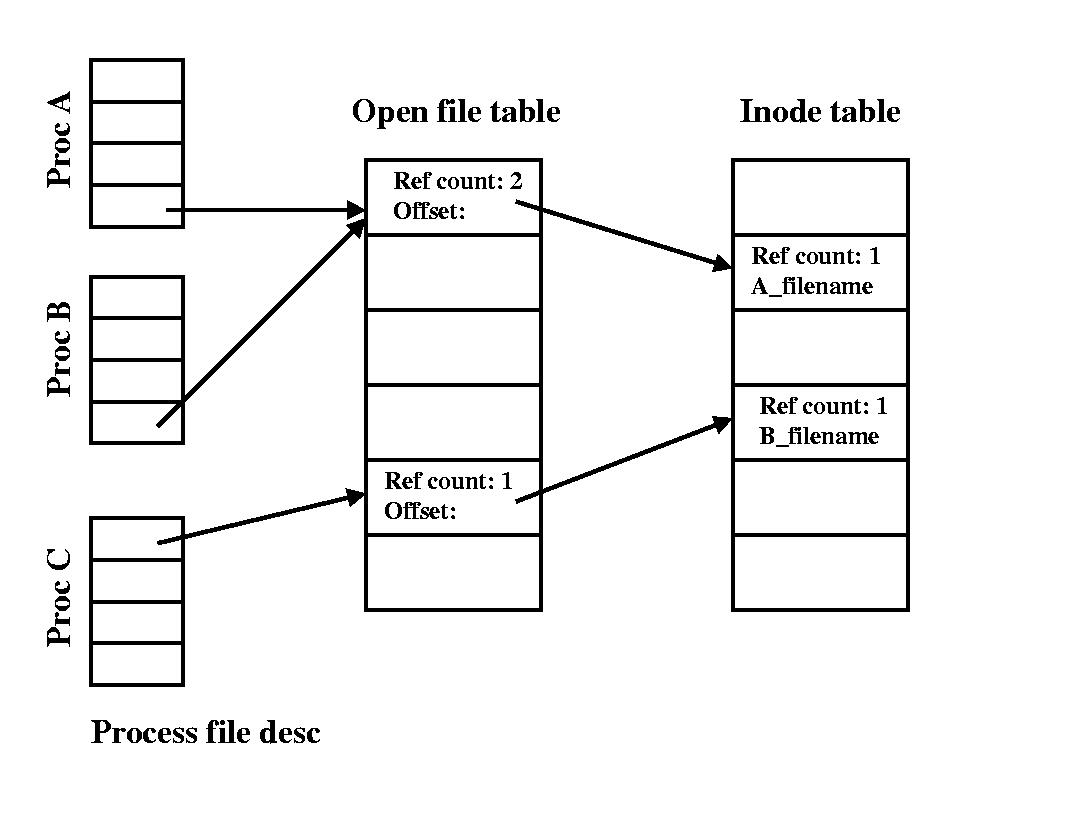
- in this example
- Proc A has forked Proc B, thereby copying file descriptors
- reference count on open file table entry is 2 since processes share the offet value
- both of them are accessing the file A_filename
- Proc C has opened the file B_filename
- if another process had opened A_filename separately, what would
happen?
- a new open file table entry would be allocated and ref count would be set to 1
- that entry would point to the inode table entry for A_filename and its ref count would be set to 2
- file descriptor your program gets is the index into the per process file descriptor table
Summary
- a regular Unix file is accessed as a linear list of bytes
- the inode defines a map from linear byte offsets within the file to logical disk block numbers on a particular disk
- the disk driver converts logical disk numbers to track/sector disk address tuples
- an inode “lives” in a file system. Its number is the logical index from the beginning of the inode region for its home file system
- a file system consists of
- a superblock
- a contiguous array of inodes
- a set of data blocks
- the superblock is a map for the file system. It contains
- the block address of the inode array
- the size of the inode array
- a map of the free data blocks on disk
- a directory is a file, built by the kernel, that contains string-inode pairs
- a path is a chain of directories
- when a path is traversed, the kernel fetches the inodes for the constituent directories, one-at-a-time, based on the inode numbers that match the directory strings
- buffer cache caches any disk blocks in front of the disk
- process accesses file through file descriptors which
point to open file table entries which point to inde table
entries
- one inode table entry for each open file
- forked processes sharing offet into an open file have file descriptors pointing to same open file table entry
- multiple processes with the same file open point to separate open file table entries, but these point to the same inode table entry
Comments